2026-05-01:MIPL的6篇论文被ICML 2026接收
MIPL共有6篇论文被接收,研究多模态大模型细粒度视觉感知、多模态大模型分层视觉识别、美学照片重构、多模态动作质量评估、图像人物交互编辑、视频时序定位。
(1)BVS:基于贝叶斯优化的多模态大模型细粒度视觉感知框架
BVS: Bayesian Visual Search with Multimodal Large Language Model for Fine-grained Perception
作者:李耕(博士生),彭宇新
通讯作者:彭宇新
论文链接:https://mipl.pku.edu.cn/download_paper.php?fileId=202611
源代码链接:https://github.com/PKU-ICST-MIPL/BVS_ICML2026
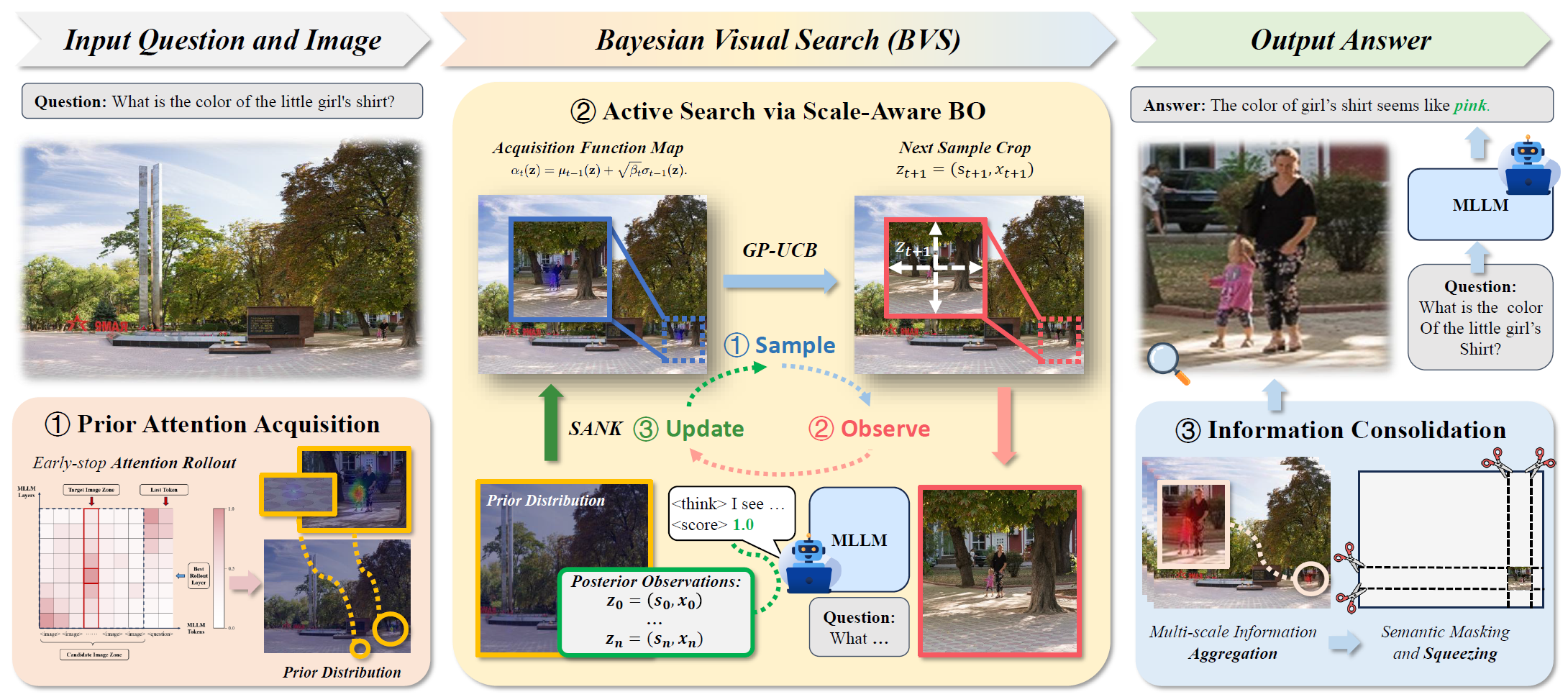
虽然多模态大模型(MLLMs)在通用任务中表现出色,但在超高分辨率(UHR)图像下的细粒度感知任务上仍面临巨大挑战,尤其是当需要从杂乱场景中识别仅占图像面积0.2%至1%的微小物体时。现有方法面临两难境地:无先验搜索方法通常需要通过低效的全图扫描来找到微小物体,精度高但耗时长;而基于先验的贪心搜索方法则缺乏后验校正机制,难以纠正由于噪声导致的关键物体漏检,速度快但精度低,这些挑战限制了多模态大模型在高精度感知任务中的实际应用。
针对上述挑战,本文提出了一种基于贝叶斯优化的视觉搜索框架BVS(Bayesian Visual Search),将视觉感知建模为连续空间(坐标-尺度流形)上的全局优化问题,实现了收敛速率受理论保障的先验引导与后验校正的协同搜索策略(次线性遗憾界)。其主要贡献包括:(1)早停注意力回溯模块:针对深层模型中存在的“注意力发散”现象,设计了早停机制,通过回溯MLLM深层中蕴含的逻辑推理注意力分布,提取出能够体现查询语义的粗粒度先验图,为搜索提供高效初始信念。(2)尺度感知的非平稳核函数:针对视觉搜索中空间相关性随缩放尺度动态变化的特性,提出了一种新型非平稳核函数,显式建模不同分辨率下的空间依赖关系,从而加速了模型在多尺度空间中的收敛速度。(3)贝叶斯优化搜索机制:引入GP-UCB算法平衡“探索”与“利用”,通过与MLLM的迭代局部观测,动态校正先验噪声并找回缺失信息,最后通过信息整合模块构建高信息密度的视觉表示。实验结果表明,在V* Bench、HR-Bench 4K/8K等多个细粒度感知基准测试中,本文提出的BVS优于ZoomEye、RAP、ViCrop等现有主流方法。在保持准确率的同时,BVS实现了更优的效能权衡,例如在HR-Bench 8K测试中,BVS仅需不到5次模型交互即可达到优于现有方法迭代20-35次的效果,证明了该框架在处理超高分辨率细粒度感知任务时的效率优势与鲁棒性。
该论文的第一作者是北京大学王选计算机研究所2023级博士生李耕,通讯作者是彭宇新教授。
(2)面向大模型分类树学习的分层表征正则化方法
Learning Taxonomic Trees with Hierarchical Representation Regularization for Large Multimodal Models
作者:何胡凌霄(博士生),谭智(硕士生),彭宇新
通讯作者:彭宇新
论文链接:https://mipl.pku.edu.cn/download_paper.php?fileId=202610
源代码链接:https://github.com/PKU-ICST-MIPL/HiR2_ICML2026
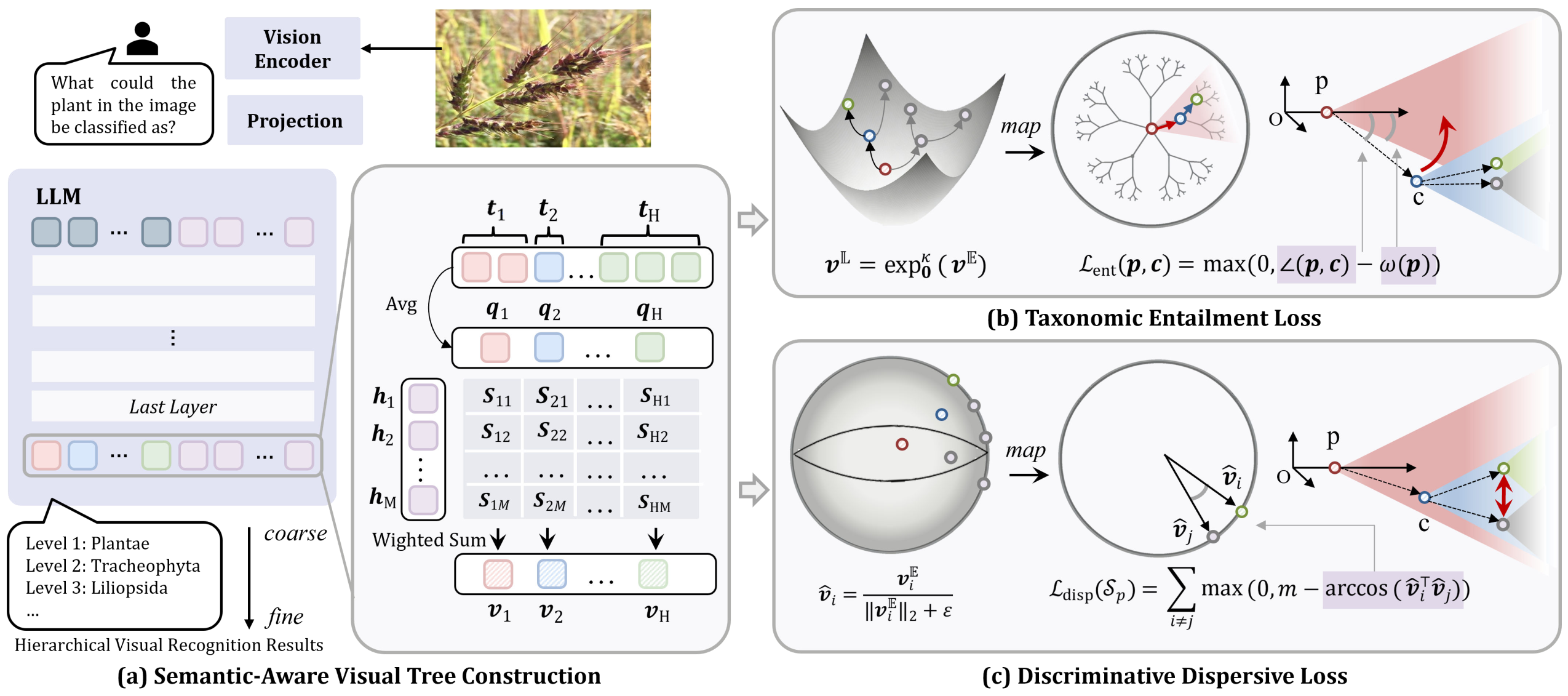
真实世界中的对象通常包含极其丰富的类别层次,形成分类树结构。以稻田中的头号恶性杂草稗草为例,类别层次从粗粒度到细粒度依次包含:植物界-被子植物门-单子叶植物纲-禾本目-禾草科-稗属-稗草(界-门-纲-目-科-属-种)。区别于传统的细粒度视觉识别(Fine-Grained Visual Recognition, FGVR),层次视觉识别(Hierarchical Visual Recognition, HVR)旨在预测所属的所有类别层次,而不仅仅预测最终的细粒度类别。如何让多模态大模型在不引入额外训练参数、几乎不增加训练开销的情况下快速学习分类树知识,从而从粗到细精准识别每一层的类别,是亟需解决的关键问题。
针对上述问题,本文提出了面向大模型分类树学习的分层表征正则化方法(Hierarchical Representation Regularization),用于在大模型表征空间中建模分类树结构,包括如下3个步骤:(1)视觉表征树构建:利用各层次类别名称对应的文本特征作为查询,对大模型最后一层的图像词元表征进行注意力聚合,得到与各个类别层次对齐的视觉表征。(2)分层蕴含约束:将各层次视觉表征映射到双曲空间,约束子类节点表征落入父类节点表征的蕴含锥区域内,保持父子类别间的包含关系。(3)判别分散约束:将同一父节点下的视觉表征投影至单位球面,增大兄弟类别间的角度距离,提高同层类别间的可分性。实验结果表明,与仅依赖语言建模目标的大模型微调方法相比,本方法能够在不引入额外训练参数、几乎不增加训练开销的情况下,使大模型内部视觉表征更符合分类树结构,从而提升分层视觉识别的跨层一致性和同层判别性。
该论文的第一作者是北京大学王选计算机研究所2023级博士生何胡凌霄,通讯作者是彭宇新教授。
(3)AesFormer:基于摄影语料挖掘的美学照片重构方法
AesFormer: Transform Everyday Photos into Beautiful Memories
作者:都天翔(博士生),何胡凌霄(博士生),彭宇新
通讯作者:彭宇新
论文链接:https://mipl.pku.edu.cn/download_paper.php?fileId=202612
源代码链接:https://github.com/PKU-ICST-MIPL/AesFormer_ICML2026
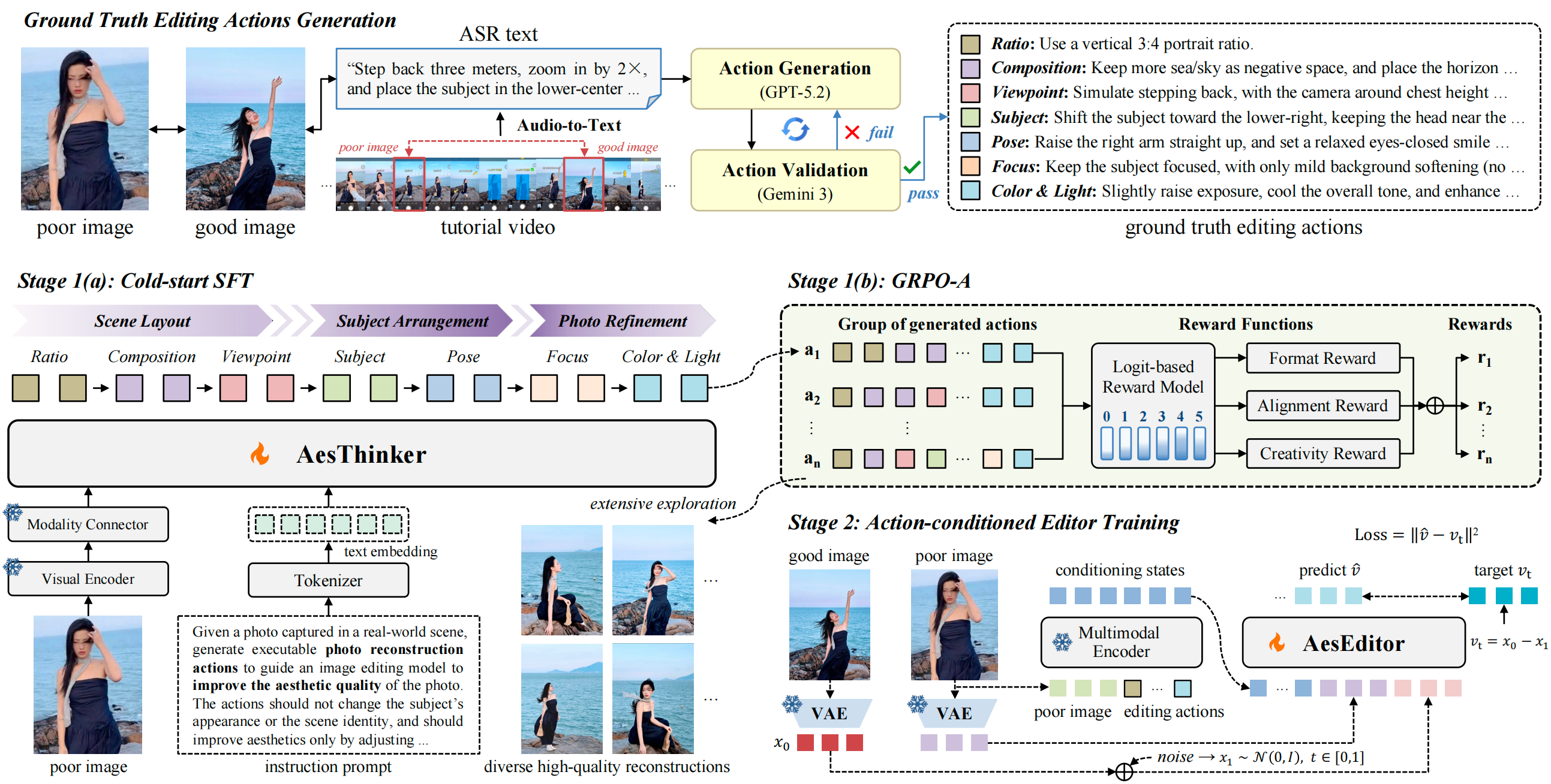
图像美化旨在提升照片的视觉质量与美学表现。然而,现有图像美化方法主要围绕色彩、光影与人物外观进行调整,难以改变图像内容与画面结构,因此无法解决构图错位、视角失衡、姿态僵硬等“结构性缺陷”。针对这一问题,本文定义了美学照片重构(Aesthetic Photo Reconstruction)任务:在保持人物身份、场景内容与整体语义基本一致的前提下,对照片的构图、视角、主体位置、人物姿态等属性进行优化,从画面结构层面实现照片美感的根本提升。然而,现有方法主要面临两个核心不足:(1)高质量美学语料稀缺:现有数据缺少反映“同一场景、同一主体、由差到优”变化过程的成对人像照片样本;(2)图像编辑模型美学能力不足:现有模型缺乏系统的摄影美学知识与审美判断能力,难以准确识别照片问题并完成合理重构。
针对上述不足,本文首先从互联网摄影教学视频中自动挖掘美学语料,构建了一个新的美学照片重构数据集与评测基准AesRecon,包含9071对“普通原片-出彩成片”人像照片样本。在此基础上,本文进一步提出理解与生成解耦的美学照片重构方法,采用“美学规划+美学编辑”的两阶段路线:第一阶段以美学规划模型作为“大脑”,生成可执行的美学优化方案;第二阶段以美学编辑模型作为“工具”,依据该方案完成照片重构。具体贡献如下:(1)美学规划模型训练:首先通过冷启动监督微调,将美学优化方案建模为符合摄影逻辑的有序决策序列,引导模型从七个递进的摄影维度分析照片问题,赋予其基础的美学理解、问题诊断与方案规划能力;随后通过美学引导的组相对策略优化,鼓励模型探索多样且合理的优化路径,进一步提升其美学规划能力与方案生成质量。(2)美学编辑模型训练:通过对图像编辑模型进行以美学优化方案为条件的流匹配训练,使其能够将抽象的美学方案稳定转化为精确的像素级编辑,从而提升其照片重构能力。实验结果表明,本文方法在所构建的美学照片重构评测基准上取得了优于现有方法的效果。
该论文的第一作者是北京大学王选计算机研究所2025级博士生都天翔,通讯作者是彭宇新教授。
(4)LIMSSR:面向训练阶段不完整多模态观测的大语言模型驱动的序列到分数推理方法
LIMSSR: LLM-Driven Sequence-to-Score Reasoning under Training-Time Incomplete Multimodal Observations
作者:许煌标(博士生),吴涣祺(博士生),柯逍,彭宇新
通讯作者:柯逍,彭宇新
论文链接:https://mipl.pku.edu.cn/download_paper.php?fileId=202613
源代码链接:https://github.com/XuHuangbiao/LIMSSR
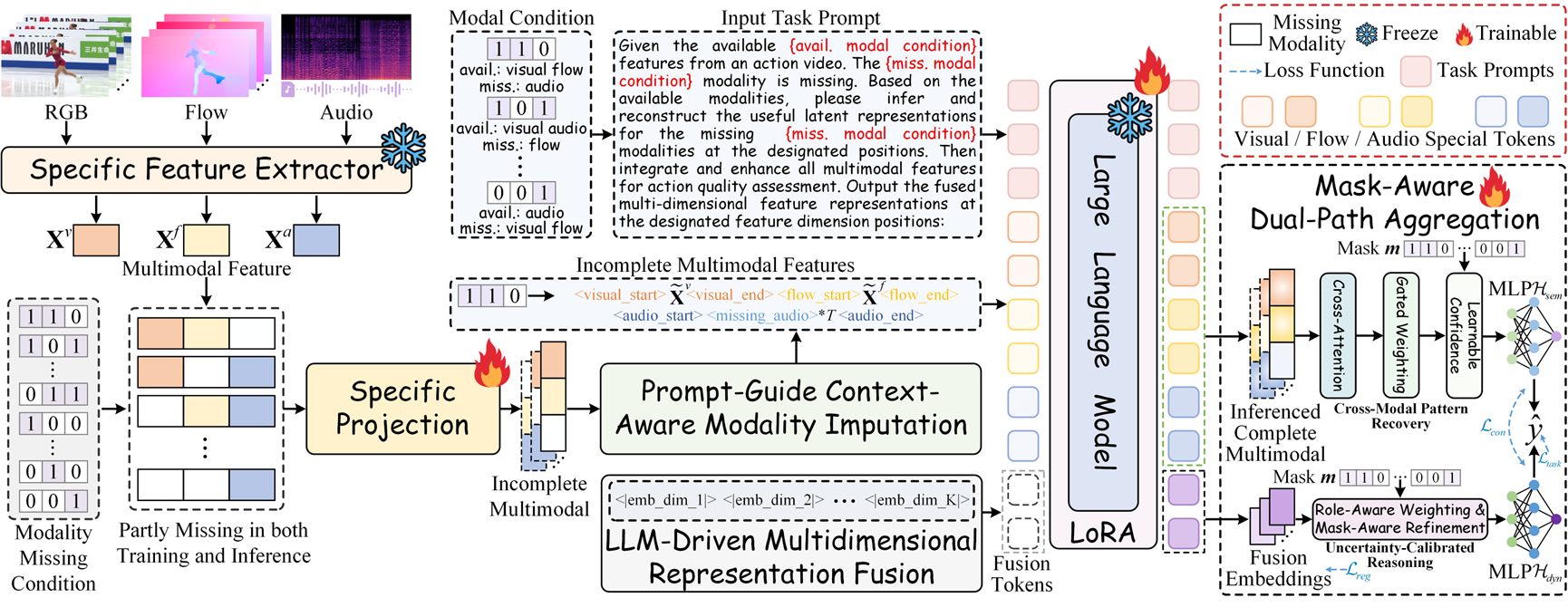
动作质量评估(Action Quality Assessment,AQA)旨在根据视频内容对动作执行质量进行精细评分,在体育评分、康复评估和技能鉴定等场景中具有重要应用价值。近年来,多模态学习为AQA带来了新的提升空间,但现实环境中的多模态数据往往并不完整,模态缺失普遍存在,例如传感器故障、隐私限制或数据损坏等情况。现有不完整多模态学习方法虽然取得了一定进展,但大多假设训练阶段能够获得完整模态数据,用于重建缺失信息或提供跨模态先验监督。这一“训练时全模态可见”的假设与真实应用场景并不一致,使得模型在面对训练阶段同样存在模态缺失的更复杂条件时,往往难以稳定发挥性能。
针对上述挑战,本文提出了一种面向训练阶段不完整多模态观测场景的全新框架:LIMSSR(LLM-Driven Incomplete Multimodal Sequence-to-Score Reasoning)。该方法首次将不完整多模态动作质量评估建模为条件序列到分数推理任务,利用大语言模型的上下文理解与语义推理能力,在无需完整训练数据监督的前提下,对缺失模态的潜在语义进行推断与融合。具体而言,(1)本文设计了提示引导的上下文感知模态补全机制,通过显式缺失词元(token)与任务提示,引导模型根据可观测上下文推断缺失模态语义;(2)进一步提出大语言模型驱动的多维表示融合模块,借助专门的融合词元(token)实现不同模态信息的深层交互与统一表达;(3)同时,为缓解缺失条件下的推理不确定性和幻觉问题,本文构建了掩码感知双路径聚合模块,将高层语义推理与低层特征恢复进行动态协同,从而提升模型在复杂缺失模式下的鲁棒性与稳定性。实验结果表明,该方法在FS1000、Fis-V和Rhythmic Gymnastics三个公开数据集上均优于现有方法,在摆脱完整训练数据依赖的同时,为面向真实场景的数据高效多模态学习提供了新的研究思路。
该论文的第一作者是福州大学计算机与大数据学院2023级博士生许煌标,通讯作者是柯逍教授和彭宇新教授,论文已被ICML 2026接收为Spotlight(前2.2%),代码已于GitHub开源。
(5)图像人物交互编辑的认知基准与基于视频生成模型的动态自纠错编辑框架
Taming I2V Models for Image HOI Editing: A Cognitive Benchmark and Agentic Self-Correcting Framework
作者:高嘉怿(博士生),陈庆超,彭宇新,刘洋
通讯作者:刘洋
论文链接:https://mipl.pku.edu.cn/download_paper.php?fileId=202614
源代码链接:https://github.com/oceanflowlab/HOI-Edit
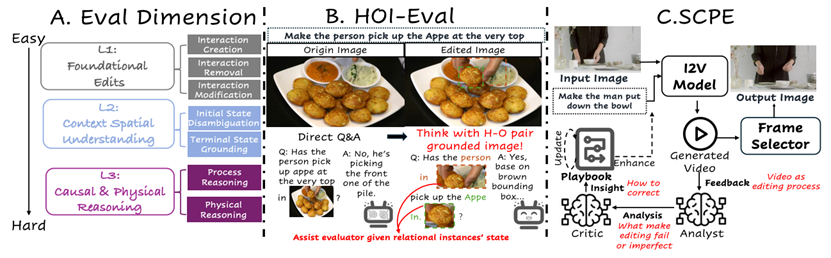
图像人物交互编辑(Image Human-Object Interactions Editing)旨在根据自然语言指令在图像中精准修改人与物体的互动关系。随着生成模型的发展,现有研究暴露出两大挑战:一是缺乏针对HOI编辑的评测基准与评估指标,已有评测局限于对静态单一的物体或者属性的编辑,且依赖全局相似度指标进行评测,无法细粒度地验证人物-物体对在编辑变化中的成对关系;二是现有方法多将交互建模为静态重绘过程,缺乏对动态交互过程与因果关系的感知与重绘能力。
为克服这些局限,本文从基准、评估与方法三方面提出解决方案。首先,我们提出了首个面向图像HOI编辑的多层次评测基准HOI-Edit,系统评估人物交互编辑的多维度认知能力。其次,提出新的评估指标HOI-Eval,基于成对区域定位的思考范式,引入空间锚点实现人物-物体对的关系验证。最后,鉴于HOI编辑的核心在于动态关系重塑,引入图像到视频(I2V)模型,利用其内在的连续帧生成能力进行动态重构,并提出SCPE,一个智能体驱动的自纠错编辑框架,通过“生成-分析-反思”闭环对I2V模型的指令进行迭代精炼并对生成视频进行抽帧,使编辑结果在交互成功率上达到可比Nano Banana的水平。
该论文的第一作者是北京大学王选计算机研究所2026级博士生高嘉怿,通讯作者是刘洋助理教授,与彭宇新教授合作完成。
(6)TaRO:面向视频时序定位的时序感知推理优化
TaRO:Temporal-Aware Reasoning Optimization for Video Temporal Grounding
作者:郑明航(博士生),尹子昊,杨怡,彭宇新,刘洋
通讯作者:刘洋
论文链接:https://mipl.pku.edu.cn/download_paper.php?fileId=202615
项目主页链接:https://github.com/oceanflowlab/TaRO
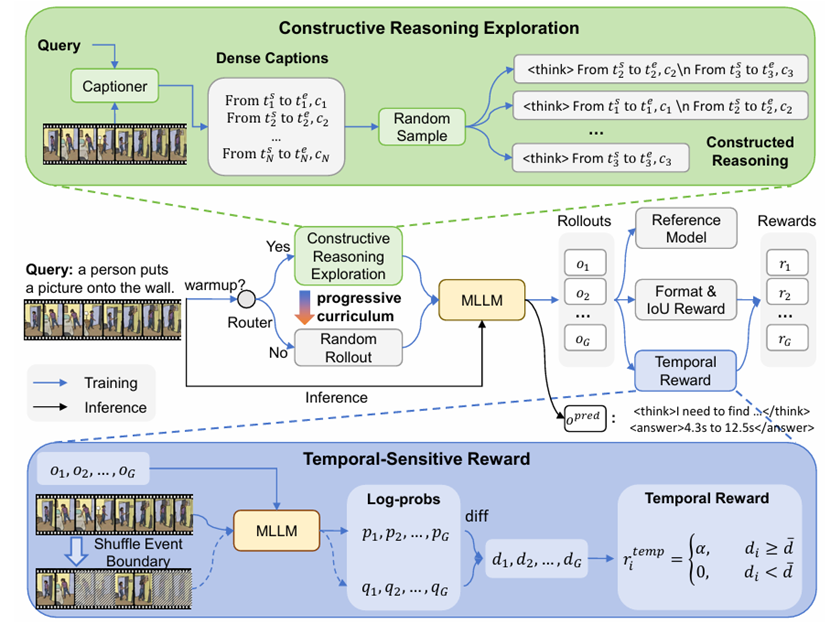
视频时序定位(Video Temporal Grounding, VTG)旨在根据自然语言查询在未剪辑视频中精准识别事件的起止时间。随着多模态大模型(MLLMs)的快速发展,引入强化学习(RL)生成推理路径以指导时序定位已成为主流趋势。然而,现有研究暴露出两大挑战:一是强化学习中的随机探索效率低下,导致模型的推理路径倾向于生成表面化的通用视频描述,无法为精准的时序定位提供有效指导;二是现有的奖励函数仅关注最终答案的正确性(如IoU),而忽略了中间推理过程的质量,使得强化后的模型难以真正依赖视觉时序证据进行泛化推理。
为克服这些局限,本文提出TaRO(时序感知推理优化),显式增强多模态大模型“带着时间思考”的能力。其主要贡献包括:(1)模板化推理探索:为打破盲目随机探索的低效性,利用预生成的带显式时间戳的密集描述构造推理路径,为模型探索高质量的时序感知推理提供有效指导;(2)时间敏感度奖励:基于高质量推理应严格锚定特定事件和时间戳的洞察,通过局部打乱真实时间边界附近的视频帧来评估推理质量。若推理有效,关键帧的时序破坏会导致推理置信度显著下降,模型以此置信度下降作为奖励信号,被强制要求生成与时序证据紧密耦合的推理;(3)渐进式课程学习:设计了从利用该奖励选择高质量模板化构造推理,逐步演进到模型自由探索并自主生成有效推理的阶段性训练范式。该方法有效改善了表面化推理的问题,并在四个公开VTG基准上取得了最佳的零样本性能。
该论文的第一作者是北京大学王选计算机研究所2022级博士生郑明航,通讯作者是刘洋助理教授,与彭宇新教授合作完成。