
2026-04-14:MIPL的1篇论文被TIP期刊接收
IEEE Transactions on Image Processing (TIP)是图像处理与计算机视觉领域的国际学术期刊,中国计算机学会(CCF)推荐的A类期刊,主要关注图像与视频处理、分析、增强及相关算法等前沿研究,影响因子13.7。
MIPL有1篇论文被接收,研究多模态大模型的轻量化推理加速。
FinePruner: 基于注意力头级无偏细粒度视觉Token压缩的多模态大模型推理加速
FinePruner: Unbiased Attention-Head-Level Fine-grained Token Reduction for Efficient Inference of Large Vision-Language Models
作者:王梓烁(硕士生),郑翔天(博士生),彭宇新
通讯作者:彭宇新
源代码链接:https://github.com/PKU-ICST-MIPL/FinePruner_TIP2026
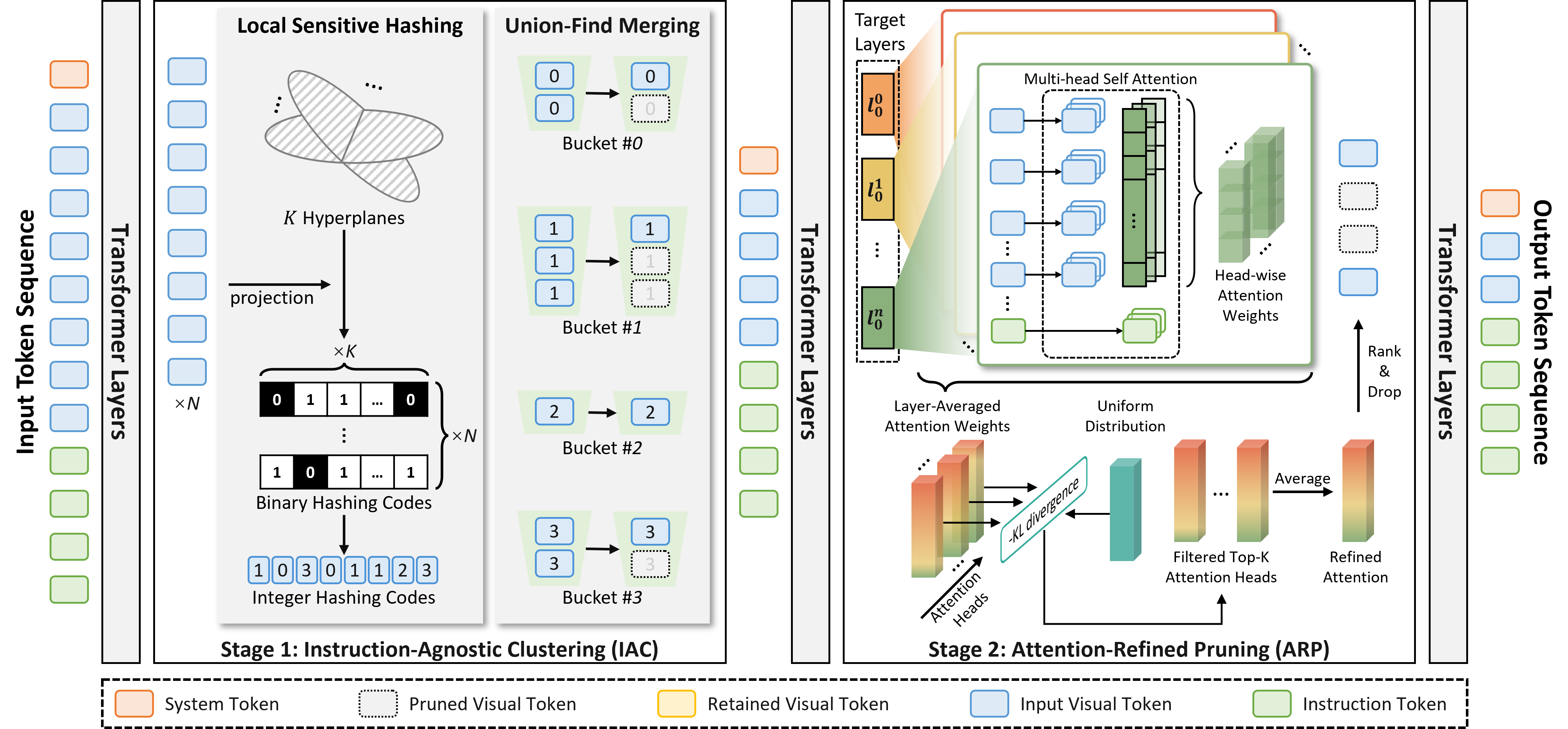
视觉Token压缩旨在从输入大模型的Token序列中删除冗余的视觉Token,缩短序列长度,降低多模态大模型的计算开销,提高推理效率。然而,现有方法面临模型加速后的精度损失问题,在具有挑战性的细粒度图像分类(Fine-Grained Visual Classification,FGVC)任务上精度损失尤其严重。本文通过实验发现,现有方法依赖注意力分布来评估视觉Token的重要性,而多模态大模型存在“注意力偏差”,视觉Token被分配的注意力分数并不等同于其重要性,一些无关视觉Token会被分配更高的注意力,而重要的视觉Token则被分配较低的注意力,导致现有方法错误地删除重要视觉Token,无法精准保留图像中的细粒度辨识性视觉信息,造成严重的精度损失。
针对上述挑战,本文提出了一种注意力头级的无偏细粒度视觉Token压缩方法FinePruner,旨在克服“注意力偏差”的影响,从输入序列中精准保留重要的视觉Token,在加速推理的同时避免精度受损。具体来说,本文首先通过可视化实验分析了“注意力偏差”的分布规律,得出两个结论:(1)浅层中的注意力偏差比深层中更加严重,(2)注意力偏差主要并非存在于所有注意力头中,部分注意力头基本不受影响。基于上述结论,本文首先在浅层网络中进行指令无关的视觉Token聚类,此时注意力偏差较为严重,因此仅根据视觉Token的语义相似度,利用局部敏感哈希和并查集合并算法,将语义相似的视觉Token放入同一个聚类簇,并在每个聚类簇中保留第一个视觉Token,从而在保留多样性的同时初步降低视觉Token冗余程度。然后,在深层网络中进行注意力修正的视觉Token剪枝,此时注意力偏差已经减弱,本文进一步根据注意力分布与均匀分布之间的KL散度,筛选出注意力分布平滑、受偏差影响较小的注意力头,根据其注意力分布对视觉Token进行排序,并删除注意力较低的视觉Token,进一步缩短序列长度,实现推理加速。在5个细粒度图像分类和5个视觉问答评测基准上的实验表明,与当前最优方法相比,本方法能够实现更好的精度-速度权衡,在相同速度下精度更高,相同精度下速度更快。
该论文的第一作者是北京大学王选计算机研究所2023级硕士生王梓烁,通讯作者是彭宇新教授。
MIPL有1篇论文被接收,研究多模态大模型的轻量化推理加速。
FinePruner: 基于注意力头级无偏细粒度视觉Token压缩的多模态大模型推理加速
FinePruner: Unbiased Attention-Head-Level Fine-grained Token Reduction for Efficient Inference of Large Vision-Language Models
作者:王梓烁(硕士生),郑翔天(博士生),彭宇新
通讯作者:彭宇新
源代码链接:https://github.com/PKU-ICST-MIPL/FinePruner_TIP2026
视觉Token压缩旨在从输入大模型的Token序列中删除冗余的视觉Token,缩短序列长度,降低多模态大模型的计算开销,提高推理效率。然而,现有方法面临模型加速后的精度损失问题,在具有挑战性的细粒度图像分类(Fine-Grained Visual Classification,FGVC)任务上精度损失尤其严重。本文通过实验发现,现有方法依赖注意力分布来评估视觉Token的重要性,而多模态大模型存在“注意力偏差”,视觉Token被分配的注意力分数并不等同于其重要性,一些无关视觉Token会被分配更高的注意力,而重要的视觉Token则被分配较低的注意力,导致现有方法错误地删除重要视觉Token,无法精准保留图像中的细粒度辨识性视觉信息,造成严重的精度损失。
针对上述挑战,本文提出了一种注意力头级的无偏细粒度视觉Token压缩方法FinePruner,旨在克服“注意力偏差”的影响,从输入序列中精准保留重要的视觉Token,在加速推理的同时避免精度受损。具体来说,本文首先通过可视化实验分析了“注意力偏差”的分布规律,得出两个结论:(1)浅层中的注意力偏差比深层中更加严重,(2)注意力偏差主要并非存在于所有注意力头中,部分注意力头基本不受影响。基于上述结论,本文首先在浅层网络中进行指令无关的视觉Token聚类,此时注意力偏差较为严重,因此仅根据视觉Token的语义相似度,利用局部敏感哈希和并查集合并算法,将语义相似的视觉Token放入同一个聚类簇,并在每个聚类簇中保留第一个视觉Token,从而在保留多样性的同时初步降低视觉Token冗余程度。然后,在深层网络中进行注意力修正的视觉Token剪枝,此时注意力偏差已经减弱,本文进一步根据注意力分布与均匀分布之间的KL散度,筛选出注意力分布平滑、受偏差影响较小的注意力头,根据其注意力分布对视觉Token进行排序,并删除注意力较低的视觉Token,进一步缩短序列长度,实现推理加速。在5个细粒度图像分类和5个视觉问答评测基准上的实验表明,与当前最优方法相比,本方法能够实现更好的精度-速度权衡,在相同速度下精度更高,相同精度下速度更快。
该论文的第一作者是北京大学王选计算机研究所2023级硕士生王梓烁,通讯作者是彭宇新教授。